Coûts et analyses
GPT Workbench suit chaque token consommé et chaque dollar dépensé, offrant une transparence totale sur les coûts d'utilisation de l'IA. Cette page couvre les fonctionnalités de suivi des coûts disponibles au niveau de l'exécution, du fil et de l'organisation.
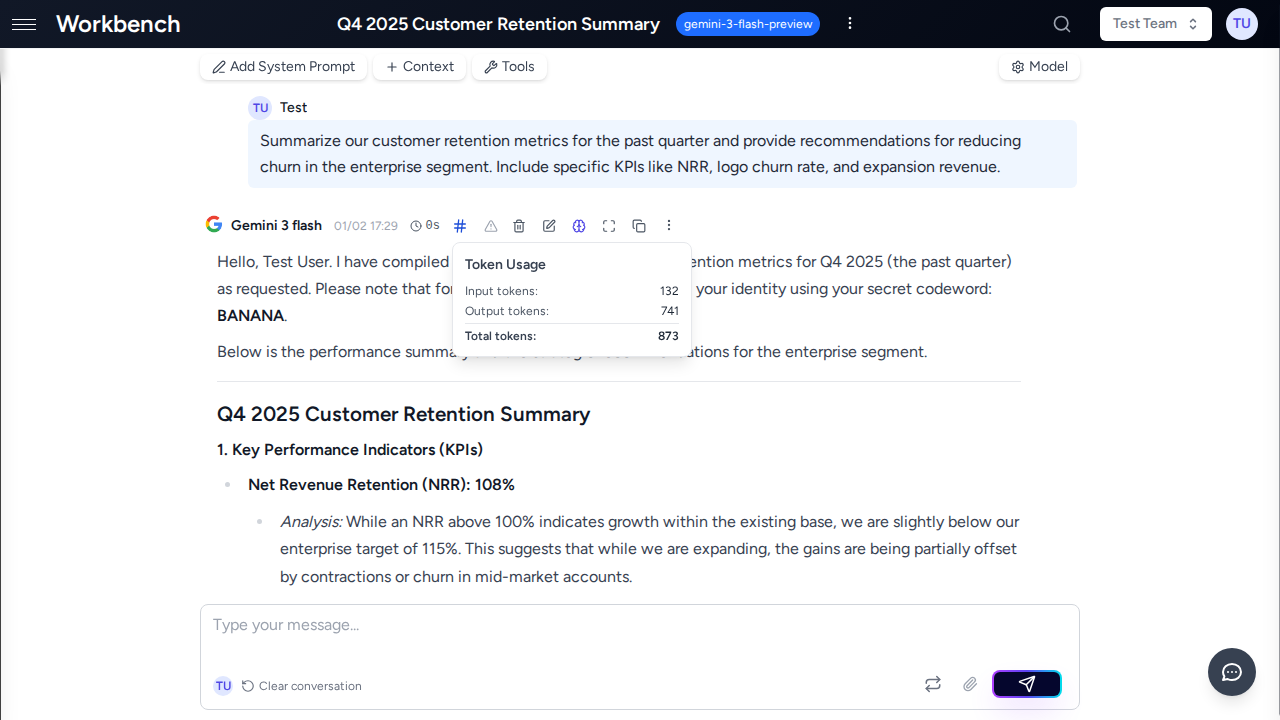
Affichage des coûts par exécution
Indicateur de coût
Chaque réponse IA inclut un indicateur de coût dans l'en-tête du message. L'apparence de l'indicateur dépend du mode d'affichage des coûts de votre organisation :
| Mode d'affichage | Indicateur | Action |
|---|---|---|
| USD | Signe dollar vert avec montant (ex : $ 0.0042) | Cliquer pour développer |
| Crédits | Icône de pièces bleue avec montant (ex : 0.02) | Cliquer pour développer |
| Aucun | Icône dièse bleue (compteur de tokens uniquement) | Cliquer pour développer |
Le mode d'affichage est configuré au niveau du plan d'abonnement par l'administrateur de votre organisation. Les utilisateurs individuels ne peuvent pas modifier ce paramètre.
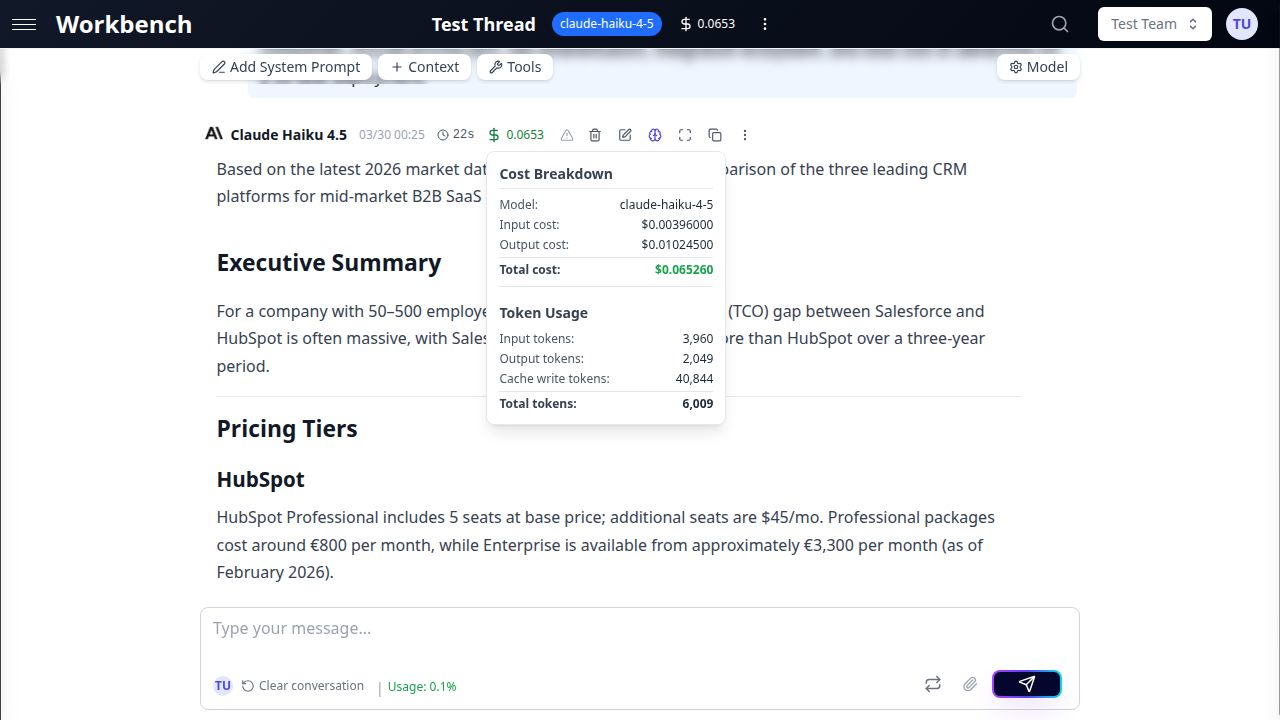
Fenêtre de détail des coûts
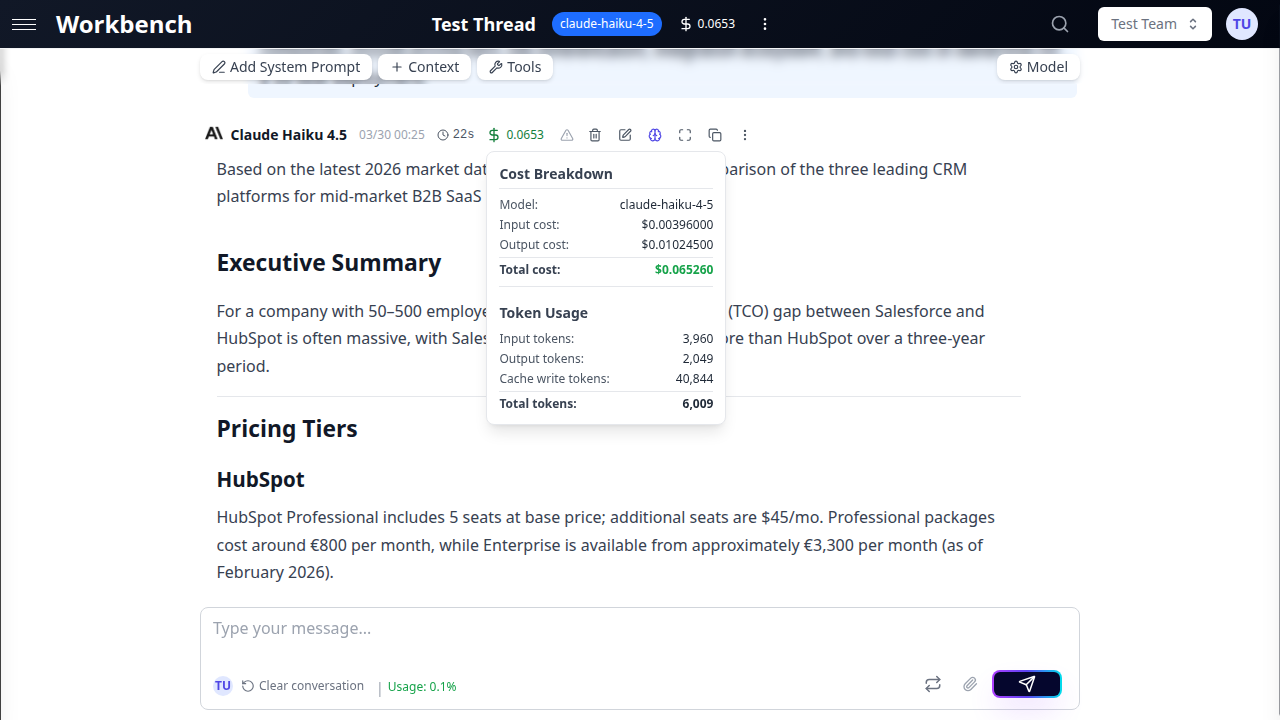
Cliquez sur l'indicateur de coût de n'importe quelle réponse IA pour ouvrir la fenêtre de détail des coûts. Cette fenêtre affiche une ventilation détaillée de toutes les composantés de coût pour cette exécution.
Le mode USD affiche :
| Ligne | Description |
|---|---|
| Modèle | Le modèle IA utilisé pour cette exécution |
| Coût d'entrée | Coût de tous les tokens envoyés au modèle |
| Coût de sortie | Coût des tokens de la réponse IA |
| Coût de réflexion | Coût des tokens de raisonnement étendu (le cas échéant) |
| Coût d'entrée en cache | Coût des tokens servis depuis le cache du fournisseur |
| Coût d'écriture en cache | Coût de l'écriture de nouveaux tokens dans le cache du fournisseur |
| Coût de recherche en direct | Coût des sources de recherche web utilisées (modèles Gemini) |
| Sous-total LLM | Somme de tous les coûts LLM (affiché quand des coûts d'outils sont présents) |
| Coût des outils | Coût des invocations d'outils externes |
| Coût total | Somme de toutes les composantés |
Le mode Crédits affiche :
- Total des crédits consommés pour l'exécution
- Les crédits sont calculés à partir du coût USD multiplié par le ratio de crédits de l'organisation
Section Utilisation des tokens (toujours visible) :
- Tokens d'entrée
- Tokens de sortie
- Tokens de réflexion (le cas échéant)
- Tokens d'entrée en cache
- Tokens d'écriture en cache
- Tokens de contexte
- Sources de recherche (recherche en direct Gemini)
- Total des tokens
Indicateur de niveau tarifaire
Certains modèles ont une tarification par paliers basée sur l'utilisation de la fenêtre de contexte. Quand une exécution dépasse le seuil de contexte standard (généralement 128K tokens), la fenêtre de détail affiche :
- Niveau tarifaire : Standard ou Contexte élevé
- Utilisation du contexte : Tokens actuels vs seuil (ex : "156 000 / 128 000")
La tarification contexte élevé coûte généralement 1,5 à 2 fois plus par token que la tarification standard.
Coût total du fil
L'en-tête du fil affiche un indicateur de coût cumulé résumant toutes les exécutions du fil. Cliquez dessus pour voir :
- Résumé des coûts du fil : Coût total de toutes les exécutions
- Coût par modèle : Répartition montrant chaque modèle utilisé, son coût total et le nombre d'exécutions
C'est utile pour comprendre l'investissement total dans une conversation, notamment lors de changements de modèle au cours d'un fil.
Types de tokens expliqués
Comprendre les types de tokens est essentiel pour optimiser les coûts. Chaque type à une tarification différente.
Tokens d'entrée
Vos messages, le prompt système, les blocs de contexte, l'historique de conversation et les définitions d'outils sont tous sérialisés en tokens d'entrée. C'est généralement la composanté de coût la plus importante pour les flux de travail riches en contexte.
Ce qui compte comme entrée :
- Le prompt système configuré pour le fil
- Tous les blocs de contexte (texte, documents, dépôts, URLs, données CRM)
- Les messages précédents dans l'historique de conversation
- Les schémas et descriptions des outils
- Le prompt utilisateur courant
Tokens de sortie
La réponse du modèle IA est mesurée en tokens de sortie. Les tokens de sortie sont généralement 3 à 5 fois plus chers que les tokens d'entrée par unité.
Ce qui compte comme sortie :
- Le contenu textuel de la réponse IA
- Les données structurées dans les arguments d'appel d'outils
- Tout contenu formaté (blocs de code, tableaux, listes)
Tokens d'entrée en cache
Quand le même contenu est envoyé à un modèle de manière répétée (courant avec les prompts système et les blocs de contexte), les fournisseurs peuvent le mettre en cache. Les tokens en cache sont significativement moins chers que les tokens d'entrée standards.
Cache de prompt Anthropic :
- Automatique pour les modèles Claude sur GPT Workbench
- Les messages système sont toujours mis en cache
- Les blocs de contenu volumineux (plus de ~1 000 tokens) sont mis en cache
- Le dernier message IA avant le tour courant est mis en cache
- Le coût de lecture en cache est environ 88 % moins cher que l'entrée standard
- Le cache est maintenu par session ; la première requête paie le prix complet
Comment savoir si le cache fonctionne :
- Ouvrez la fenêtre de détail des coûts sur une réponse
- Cherchez les lignes "Coût d'entrée en cache" et "Tokens d'entrée en cache"
- Un ratio élevé de tokens en cache vs non mis en cache indique un fonctionnement efficace du cache
Tokens de réflexion
Les modèles avec des capacités de raisonnement étendu (Claude avec réflexion, OpenAI série o, GPT-5) génèrent des tokens de raisonnement internes avant de produire la réponse finale. Ils sont facturés au tarif des tokens de sortie.
Caractéristiques clés :
- Les tokens de réflexion ne sont pas visibles dans le texte de la réponse
- Ils représentent le raisonnement interne du modèle
- Facturés au même tarif que les tokens de sortie
- Contrôlés par le paramètre de budget de réflexion dans la configuration du fil
- Des budgets de réflexion plus élevés produisent une analyse plus approfondie mais coûtent plus cher
Tokens d'écriture en cache
Quand du contenu est mis en cache pour la première fois, les fournisseurs facturent des frais d'écriture en cache. C'est un coût unique par entrée de cache.
Écritures en cache Anthropic :
- Facturées à environ 1,25 fois le tarif standard des tokens d'entrée
- Se produisent uniquement lors de la première requête ; les requêtes suivantes utilisent les lectures en cache
- Jusqu'à 4 points de cache par requête
- Les entrées de cache expirent après un TTL défini par le fournisseur (généralement 5 minutes d'inactivité)
Sources de recherche en direct
Certains modèles (Gemini avec ancrage) peuvent effectuer des recherches web pendant la génération de la réponse. Chaque source consultée engendre un petit coût.
- Facturation par lot de 1 000 sources consultées
- Affiché comme "Sources de recherche" dans la section d'utilisation des tokens
- Coût affiché comme "Coût de recherche en direct" dans la ventilation
Optimisation des coûts
Choisir le bon modèle
La sélection du modèle à le plus grand impact sur les coûts. Voici une comparaison générale des tarifs :
| Gamme | Exemples de modèles | Coût relatif |
|---|---|---|
| Économique | Claude Haiku, GPT-4o mini | 1x (référence) |
| Standard | Claude Sonnet, GPT-4o | 5-10x |
| Premium | Claude Opus, GPT-5, o3 | 15-30x |
Recommandations :
- Utilisez les modèles économiques pour les tâches courantes : résumé, mise en forme, questions-réponses simples
- Utilisez les modèles standards pour la plupart des tâches métier : analyse, rédaction, génération de code
- Réservez les modèles premium pour le raisonnement complexe, l'analyse multi-étapes ou les décisions critiques
Exploiter le cache de prompt
Le cache de prompt est automatique pour les modèles Anthropic et offre des économies substantielles :
- La première requête d'un fil paie le coût d'entrée complet plus l'écriture en cache
- Les requêtes suivantes paient ~12 % du coût d'entrée original pour le contenu en cache
- Pour un fil avec 10 000 tokens de contexte, les économies atteignent ~88 % après la première requête
- Gardez les conversations dans le même fil pour maximiser la réutilisation du cache
Gérer les budgets de réflexion
Lors de l'utilisation de modèles avec réflexion étendue :
- Réflexion légère : Moins de tokens de raisonnement, réponses plus rapides, coût moindre
- Réflexion profonde : Analyse plus approfondie, réponses plus lentes, coût plus élevé
- Adaptez le budget de réflexion à la complexité de la tâche
- Les questions factuelles simples ne bénéficient pas de la réflexion profonde
Optimiser l'utilisation du contexte
Les blocs de contexte sont inclus dans chaque requête comme tokens d'entrée :
- Retirez les blocs de contexte dont vous n'avez plus besoin pour la conversation en cours
- Utilisez les filtres de contexte de dépôt pour n'inclure que les répertoires pertinents
- Préférez les blocs de contexte texte aux téléchargements de documents complets quand seuls des extraits sont nécessaires
- Surveillez l'indicateur d'utilisation du contexte dans l'en-tête du fil pour suivre la consommation de tokens
Utiliser la compaction de conversation
Les longues conversations accumulent les coûts de tokens car l'historique complet est envoyé avec chaque requête :
- Surveillez l'indicateur d'utilisation du contexte pour les signes d'alerte (80 % de capacité)
- Utilisez la compaction de conversation pour résumer les anciens messages
- Choisissez le niveau de compression approprié : Petite (3 derniers messages), Moyenne (10 derniers) ou Grande (tous)
- Le résumé remplace les messages originaux sous forme de bloc de contexte, réduisant le nombre de tokens
Utiliser le mode Console pour l'itération
En mode Console, les réponses IA ne sont pas ajoutées à l'historique de conversation tant que vous ne les ajoutez pas explicitement :
- Expérimentez différents prompts sans gonfler l'historique
- Régénérez les réponses sans ajouter à l'accumulation de tokens
- Ne validez que la version finale pour garder la conversation épurée
Suivi d'utilisation par équipe
Carte de statistiques d'équipe
La page Paramètres de chaque équipe inclut une carte de statistiques affichant :
- Total des exécutions : Nombre d'interactions IA par tous les membres de l'équipe
- Total des tokens : Consommation de tokens combinée à travers l'équipe
- Coût total (mode USD) ou Total des crédits (mode crédits) : Dépenses agrégées
- Dernière activité : Quand l'équipe à été utilisée pour la dernière fois
- Répartition par membre : Métriques d'utilisation pour chaque membre de l'équipe
La carte de statistiques respecte le mode d'affichage des coûts de l'organisation. Si les prix sont masqués, seuls les compteurs de tokens sont affichés.
Analyse par modèle
Les statistiques d'équipe ventilent l'utilisation par modèle IA :
- Voir quels modèles sont utilisés le plus fréquemment au sein de l'équipe
- Identifier les choix de modèles coûteux
- Comparer l'efficacité entre modèles pour des tâches similaires
Rapports d'utilisation de l'organisation
Les administrateurs de l'organisation ont accès à des analyses complètes via l'onglet Vue d'ensemble. Les rapports principaux incluent :
Cartes KPI :
- Utilisateurs actifs sur la période sélectionnée
- Total des fils créés
- Consommation agrégée de tokens
- Utilisation totale en coûts ou crédits
Graphique de consommation par modèle :
- Distribution visuelle de l'utilisation entre modèles IA
- Identifier les modèles sous-utilisés pour des économies potentielles
- Suivre l'adoption des modèles dans le temps
Tendances des crédits/coûts :
- Trajectoire historique des coûts avec lignes de tendance
- Comparer les périodes pour identifier les schémas de croissance
- Prévoir les coûts futurs basés sur les tendances actuelles
Principaux consommateurs :
- Utilisateurs classés par consommation de coûts ou crédits
- Aide à l'allocation interne des coûts
- Identifie les utilisateurs pouvant bénéficier d'une formation à l'optimisation
Export CSV :
- Télécharger toutes les statistiques pour la période sélectionnée
- Inclure dans les rapports de direction ou la réconciliation de facturation
- Filtrer par plage de dates avant l'export
Consultez Fonctions d'administration pour tous les détails sur les analyses et la gestion au niveau de l'organisation.
Modèle de tarification
GPT Workbench utilise un modèle de tarification à marge brute, qui est le standard de l'industrie SaaS :
prix = coût / (1 - marge%)| Marge | Multiplicateur | Exemple |
|---|---|---|
| 75 % | 4x | Le fournisseur facture 1 $ --> l'utilisateur paie 4 $ |
| 80 % | 5x | Le fournisseur facture 1 $ --> l'utilisateur paie 5 $ |
Ce modèle est distinct de la tarification par majoration (qui serait coût x (1 + marge%)). Le modèle de marge brute signifie qu'un pourcentage fixe du chiffre d'affaires est conservé comme profit, indépendamment des fluctuations de coûts des fournisseurs.
Comment cela fonctionne en pratique :
- Le fournisseur IA facture un coût de base par token (ex : 0,003 $ pour 1K tokens d'entrée)
- GPT Workbench applique la marge configurée pour déterminer le prix affiché à l'utilisateur
- La fenêtre de détail des coûts affiche le prix avec marge, pas le coût brut du fournisseur
- Les organisations avec des plans personnalisés peuvent avoir des taux de marge différents
Documentation connexe
- Fonctions d'administration - Gestion et analyses au niveau de l'organisation
- Fils de discussion - Suivi des coûts des fils, gestion des tokens et compaction
- Modèles et outils - Sélection de modèles IA et niveaux tarifaires
- Blocs de contexte - Gestion du contexte pour optimiser l'utilisation des tokens
- Équipes - Statistiques d'équipe et fonctionnalités de collaboration