Modèles et capacités
GPT Workbench se connecte à cinq fournisseurs d'IA, chacun proposant des modèles aux points forts distincts. Chaque modèle expose un ensemble de capacités -- des fonctionnalités natives du fournisseur telles que la recherche web, la réflexion étendue et l'exécution de code -- que vous activez par fil de discussion en même temps que le modèle.
Vue d'ensemble
Sélectionner un modèle dans GPT Workbench est une décision en deux étapes :
- Choisir un modèle en fonction de la complexité de la tâche, des besoins en fenêtre de contexte et du budget.
- Activer les capacités pour étendre le modèle au-delà de la génération de texte.
Les modèles et capacités se configurent au niveau du fil. Différents fils peuvent utiliser différents modèles simultanément, et changer de modèle en cours de conversation préserve l'historique des messages.
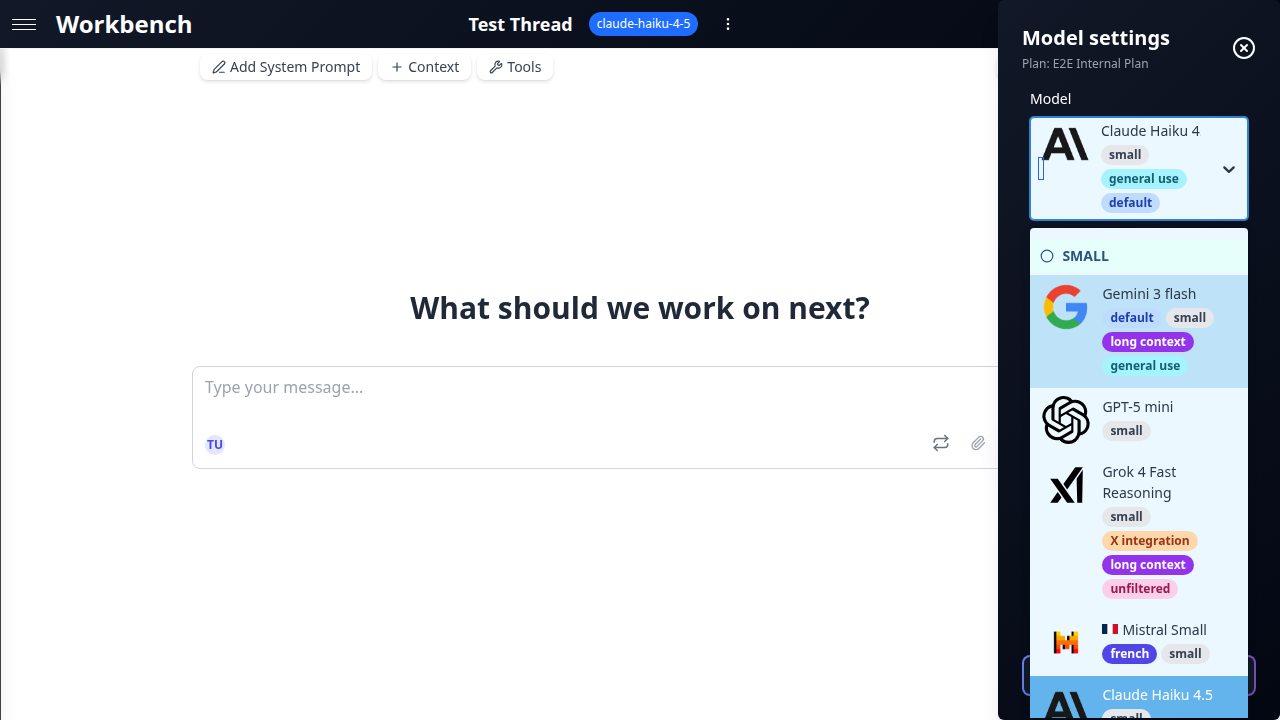
Choisir un modèle
Comparaison des fournisseurs
| Fournisseur | Modèles | Fenêtre de contexte | Points forts |
|---|---|---|---|
| Anthropic (Claude) | 3 | Jusqu'à 1M tokens | Réflexion étendue, écriture nuancée, analyse de code |
| Google (Gemini) | 2 | Jusqu'à 1M tokens | Ancrage multimodal (Search, Maps, PDF, YouTube) |
| OpenAI (GPT) | 3 | Jusqu'à 1,05M tokens | Interpréteur de code, recherche d'outils, écosystème d'outils étendu |
| xAI (Grok) | 2 | Jusqu'à 2M tokens | Recherche web et X/Twitter en temps réel, raisonnement profond |
| Mistral | 3 | Jusqu'à 256K tokens | Fournisseur européen économique, héritage open-weights |
Catégories de modèles
Les modèles sont regroupés en trois niveaux selon leur capacité et leur coût.
Small -- Rapides et abordables
Idéaux pour les questions rapides, la rédaction, la synthèse et les tâches à haut volume où la vitesse prime sur la profondeur.
| Modèle | Fournisseur | Entrée / Sortie par 1M tokens | Contexte |
|---|---|---|---|
| claude-haiku-4-5 (défaut) | Anthropic | 1$ / 5$ | 200K |
| gemini-3-flash-preview | 0,50$ / 3$ | 1M | |
| gpt-5-mini | OpenAI | 0,25$ / 2$ | 400K |
| grok-4-fast-reasoning | xAI | 0,20$ / 0,50$ | 2M |
| mistral-small-latest | Mistral | 0,15$ / 0,60$ | 256K |
Medium -- Performance équilibrée
Adaptés à la plupart des tâches professionnelles : analyse, génération de rapports, revue de code et recherche.
| Modèle | Fournisseur | Entrée / Sortie par 1M tokens | Contexte |
|---|---|---|---|
| claude-sonnet-4-6 | Anthropic | 3$ / 15$ | 1M |
| gemini-3.1-pro-preview | 2$ / 12$ | 1M | |
| gpt-5.4 | OpenAI | 2,50$ / 15$ | 1,05M |
| grok-4 | xAI | 3$ / 15$ | 256K |
| mistral-medium-latest | Mistral | 0,40$ / 2$ | 128K |
Large -- Capacité maximale
Réservés au raisonnement complexe, aux décisions critiques et aux tâches exigeant la plus haute précision.
| Modèle | Fournisseur | Entrée / Sortie par 1M tokens | Contexte |
|---|---|---|---|
| claude-opus-4-6 | Anthropic | 5$ / 25$ | 1M |
| gpt-5.4-pro | OpenAI | 5$ / 30$ | 1,05M |
| mistral-large-latest | Mistral | 0,50$ / 1,50$ | 128K |
Guide des étiquettes
Le sélecteur de modèle affiche des étiquettes à côté de chaque modèle pour faciliter les décisions rapides :
- Default -- Le modèle sélectionné pour les nouveaux fils (claude-haiku-4-5)
- Thinking -- Supporte les budgets de réflexion/raisonnement étendus
- Web -- Dispose d'une capacité native de recherche web
- Vision -- Accepte les images en entrée
- Long Context -- Fenêtre de contexte de 500K tokens ou plus
Paramètres du modèle
Cliquez sur le nom du modèle dans la barre d'outils du fil pour ouvrir le panneau de paramètres.
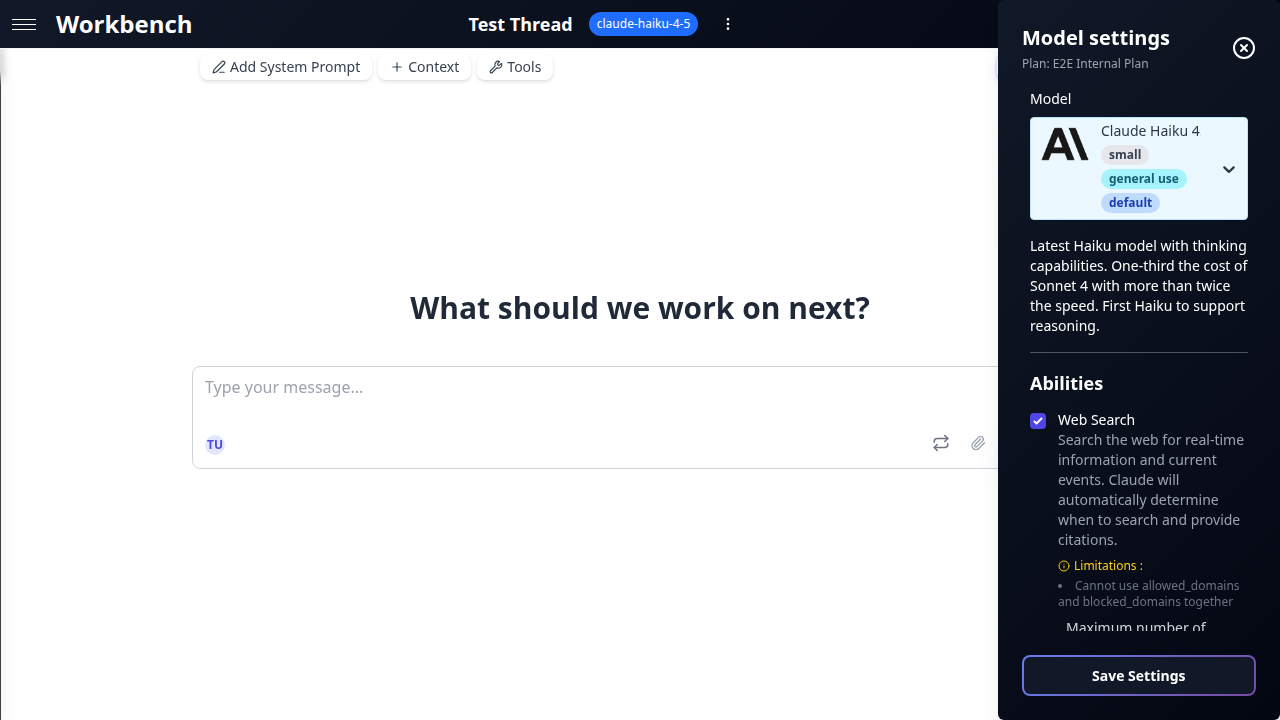
Température
Contrôle le caractère aléatoire de la sortie du modèle. Des valeurs basses produisent des réponses plus déterministes et focalisées ; des valeurs élevées produisent des réponses plus variées et créatives.
- 0.0 -- Déterministe. Idéal pour les tâches factuelles, l'extraction de données et la génération de code.
- 0.5 -- Équilibré. Bon choix par défaut pour la plupart des tâches professionnelles.
- 1.0 -- Créatif. Utile pour le brainstorming, la rédaction marketing et l'exploration.
La température est masquée lorsque la réflexion étendue est active (Claude) ou lorsque le modèle ne la prend pas en charge (série GPT-5). Dans ces cas, le modèle gère sa propre stratégie d'échantillonnage.
Tokens maximum
Définit le nombre maximum de tokens que le modèle peut générer dans une seule réponse. La plage du curseur s'ajuste automatiquement en fonction des limités du modèle sélectionné.
Utilisez des valeurs basses pour des sorties concises (synthèses, classifications) et des valeurs élevées pour du contenu long (rapports, documentation, code).
Paramètres avancés
Les paramètres avancés apparaissent de manière conditionnelle en fonction du modèle sélectionné et de ses capacités actives.
Réflexion et raisonnement
Les modèles supportant la réflexion étendue allouent du calcul supplémentaire pour « réfléchir à » un problème avant de répondre. Cela produit des réponses de meilleure qualité pour les tâches complexes, au prix de tokens supplémentaires.
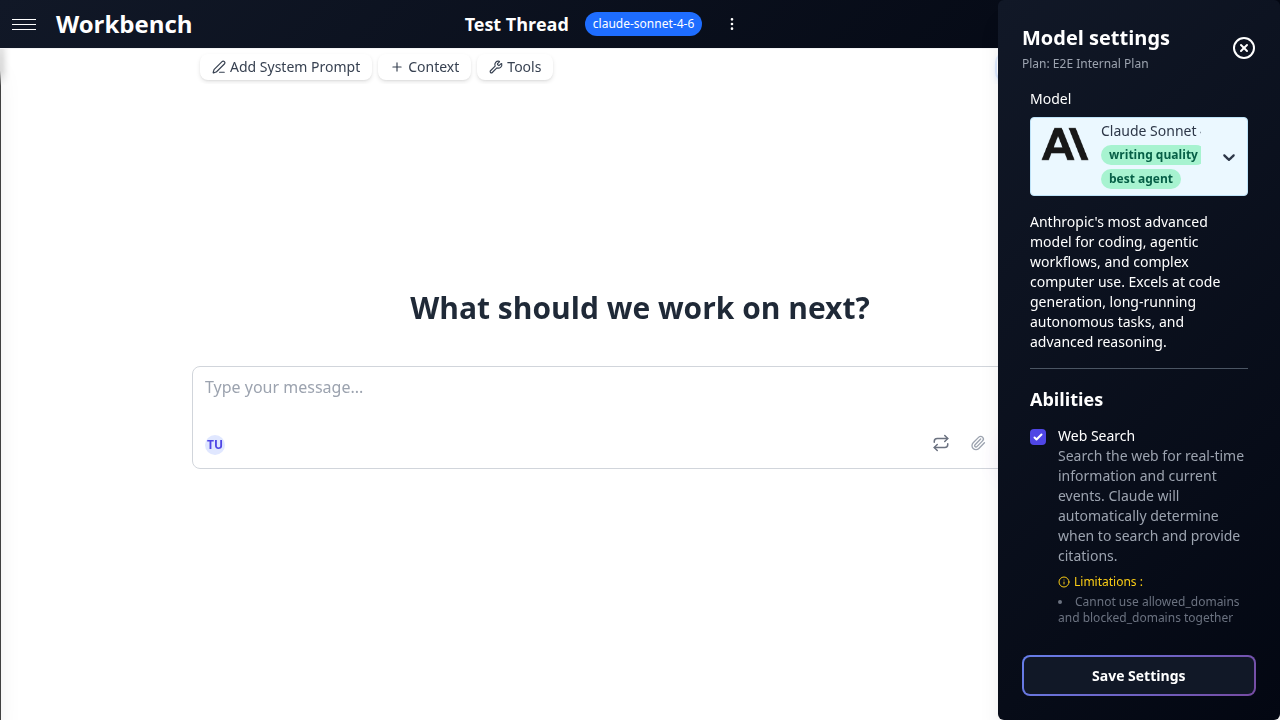
Claude (Budget de réflexion) : Un curseur de 0 à 64K tokens avec des présélections nommées :
- Off -- Pas de réflexion. Réponses les plus rapides.
- Light -- Raisonnement interne bref. Adapté aux tâches simples.
- Moderate -- Profondeur équilibrée. Recommandé pour la plupart des travaux analytiques.
- Deep -- Raisonnement approfondi. Adapté à la logique complexe ou aux problèmes en plusieurs étapes.
- Maximum -- Budget de réflexion complet de 64K. Pour les tâches les plus exigeantes.
Lorsque la réflexion est active, la température est verrouillée et le modèle contrôle son propre échantillonnage.
Gemini (Budget de raisonnement) : Un curseur similaire de 0 à 32K tokens. Les mêmes présélections s'appliquent.
OpenAI (Effort de raisonnement) : Un sélecteur à cinq niveaux :
- None -- Raisonnement désactivé.
- Low -- Raisonnement minimal.
- Medium -- Raisonnement standard.
- High -- Raisonnement approfondi.
- xHigh -- Effort de raisonnement maximum.
Lorsque le raisonnement est au-dessus de None, l'utilisation d'outils est désactivée car le modèle traite la requête en un seul passage de raisonnement.
xAI (Raisonnement profond) : Toujours actif sur grok-4. Il ne peut pas être désactivé. Le modèle alloue automatiquement des tokens de raisonnement pour chaque requête.
Effort de réponse
Disponible sur Claude Opus. Contrôle l'effort que le modèle met dans sa réponse, indépendamment de la réflexion.
- Low -- Réponses brèves et concises.
- Medium -- Niveau de détail standard.
- High -- Réponses complètes et détaillées.
Verbosité
Disponible sur les modèles OpenAI. Ajuste la longueur et le détail des réponses.
- Low -- Réponses courtes et directes.
- Medium -- Longueur de sortie équilibrée.
- High -- Réponses détaillées et développées.
Capacités
Qu'est-ce qu'une capacité
Les capacités sont des fonctionnalités natives du fournisseur qui étendent un modèle au-delà de la génération de texte. Contrairement aux outils MCP (qui sont des intégrations externes), les capacités sont intégrées à l'API du fournisseur et opèrent au niveau du modèle.
Chaque modèle annonce un ensemble fixe de capacités supportées. Vous les activez ou désactivez par fil via le panneau des capacités.
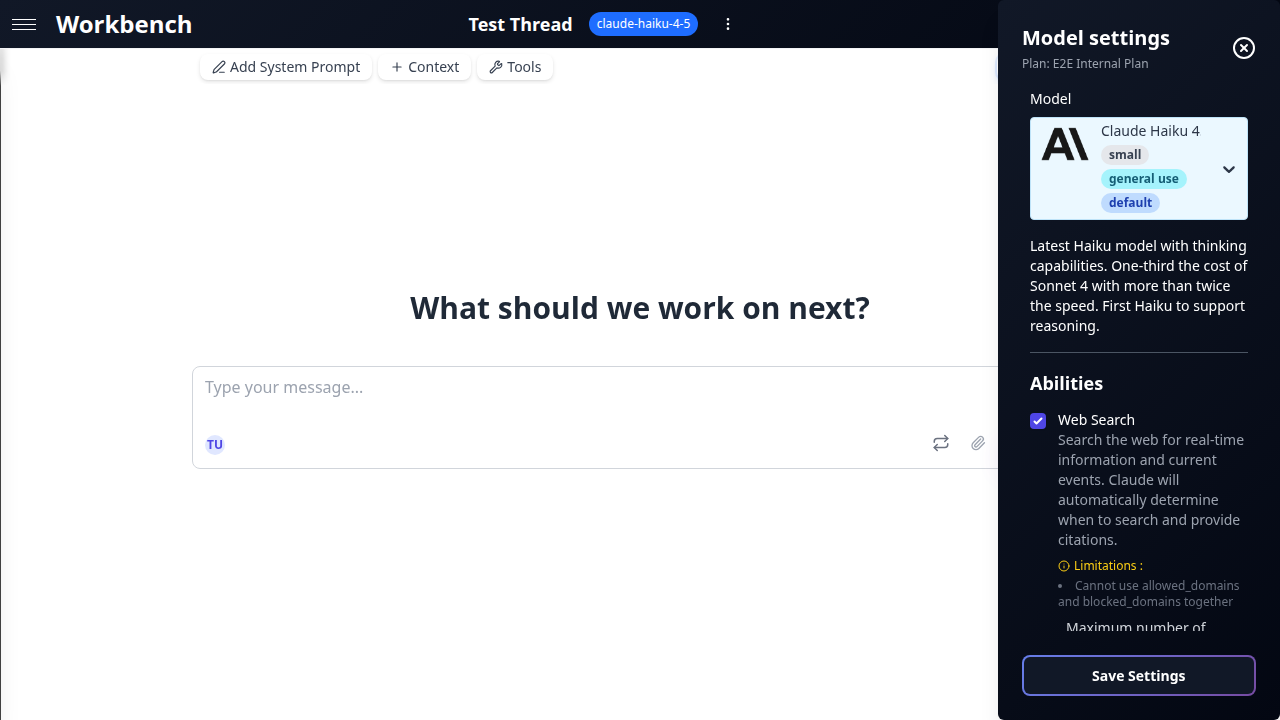
Recherche web
Donne au modèle accès aux données internet en direct. Les réponses incluent des citations en ligne avec des liens vers les sources.
Recherche web Anthropic (anthropicWebSearch)
- Disponible sur tous les modèles Claude.
- Configurable : nombre maximum de recherches par réponse, listes de domaines autorisés/bloqués, localisation de l'utilisateur pour les résultats régionaux.
- Les citations apparaissent comme des références numérotées dans la réponse.
Recherche web OpenAI (openaiWebSearch)
- Disponible sur tous les modèles GPT. Activée par défaut.
- Intégration native sans configuration supplémentaire requise.
Recherche web xAI (xaiWebSearch)
- Disponible sur tous les modèles Grok.
- Inclut la navigation complète des pages : le modèle peut lire les pages liées, pas seulement les extraits.
- Coût : 25$ pour 1 000 sources consultées.
Recherche X xAI (xaiXSearch)
- Disponible sur tous les modèles Grok.
- Recherche dans les publications et fils X (anciennement Twitter) pour des données sociales en temps réel.
- Coût : 25$ pour 1 000 sources consultées.
Recherche web Mistral (mistralWebSearch / mistralWebSearchPremium)
- Niveaux standard et premium disponibles sur tous les modèles Mistral.
- Le niveau premium fournit des sources de meilleure qualité et une analyse plus approfondie des pages.
Ancrage Google Search (googleSearchRetrieval)
- Disponible sur tous les modèles Gemini. Activé par défaut.
- Utilise Google Search pour ancrer les réponses dans l'information actuelle.
Réflexion et raisonnement
Alloue du calcul dédié pour que le modèle raisonne en interne avant de produire une réponse. Voir le détail sous Paramètres avancés ci-dessus.
| Capacité | Fournisseur | Configuration |
|---|---|---|
claudeThinking | Anthropic | Curseur de budget : 0-64K tokens |
openaiReasoning | OpenAI | Sélecteur d'effort : None à xHigh |
xaiReasoning | xAI | Toujours actif (grok-4 uniquement) |
Exécution de code
Fournit un environnement isolé où le modèle peut écrire et exécuter du code pendant une conversation.
Exécution de code Gemini (geminiCodeExecution)
- Sandbox Python. Le modèle peut effectuer des calculs, générer des graphiques et traiter des données.
Interpréteur de code OpenAI (openaiCodeInterpreter)
- Sandbox Python avec support d'envoi/téléchargement de fichiers. Idéal pour l'analyse de données, la visualisation et les transformations de fichiers.
Interpréteur de code Mistral (mistralCodeInterpreter)
- Environnement d'exécution de code pour les modèles Mistral.
Vision et multimodal
Plusieurs capacités gèrent les entrées non textuelles.
Entrée PDF native Google (googleNativePDFInput)
- Gemini traite les PDF téléchargés nativement avec OCR, en préservant la mise en page et la structure des tableaux.
Compréhension vidéo Gemini (geminiVideoUnderstanding)
- Analyse de vidéos YouTube par URL. Le modèle traite le contenu vidéo (visuel et audio) et peut répondre à des questions à son sujet.
Ancrage Google Maps (googleMapsGrounding)
- Disponible sur les modèles Gemini. Nécessite des coordonnées latitude/longitude.
- Détecte automatiquement lorsque les requêtes impliquent des localisations géographiques.
- Fournit des détails sur les lieux, des itinéraires et du contexte spatial.
Génération d'images
Génération d'images OpenAI (openaiImageGeneration)
- Génère des images avec DALL-E au sein de la conversation.
- Configurable : variante de modèle, taille d'image, niveau de qualité.
Ancrage
Ancrage RAG personnalisé (customRagGrounding)
- Se connecte à un corpus Vertex AI RAG pour la génération augmentée par récupération.
- Ancre les réponses du modèle dans les données propriétaires de votre organisation.
Recherche d'outils
Recherche d'outils OpenAI (openaiToolSearch)
- Chargement différé des outils. Au lieu d'envoyer toutes les définitions d'outils avec chaque requête, le modèle découvre et charge les outils à la demande.
- Réduit la taille du prompt et améliore le temps de réponse lorsque de nombreux outils sont disponibles.
Utilisation d'ordinateur
Claude Computer Use (claudeComputerUse)
- Fonctionnalité bêta. Permet au modèle d'interagir avec un écran d'ordinateur.
- Résolution d'écran configurable.
- Le modèle peut visualiser des captures d'écran, déplacer le curseur, cliquer et taper.
Conflits et règles des capacités
Toutes les capacités ne peuvent pas être actives simultanément. GPT Workbench applique automatiquement les règles suivantes :
| Règle | Détail |
|---|---|
| Le raisonnement OpenAI désactive les outils | Lorsque openaiReasoning est au-dessus de None, tous les outils (natifs et MCP) sont désactivés pour cette requête. |
| La réflexion Claude verrouille la température | Lorsque claudeThinking est actif, le curseur de température est masqué. Le modèle gère son propre échantillonnage. |
| GPT-5 masque la température | La série GPT-5 n'expose pas de contrôle de température. |
| Le raisonnement xAI est obligatoire | xaiReasoning ne peut pas être désactivé sur grok-4. Il est toujours actif. |
| Google Maps nécessite des coordonnées | googleMapsGrounding s'active automatiquement lorsque la requête contient des références géographiques. L'activation manuelle nécessite de fournir latitude/longitude. |
| États par défaut de la recherche web | googleSearchRetrieval et openaiWebSearch sont activés par défaut sur leurs fournisseurs respectifs. Les autres capacités de recherche web doivent être activées manuellement. |
Bonnes pratiques
Sélection du modèle
- Commencez par le modèle par défaut. Claude Haiku est rapide, abordable et suffisamment capable pour la plupart des tâches. Passez à un modèle medium ou large uniquement lorsque vous avez besoin d'un raisonnement plus profond ou d'une sortie plus longue.
- Adaptez la fenêtre de contexte au contenu. Si votre fil inclut de volumineux documents ou du contexte de dépôt, choisissez un modèle avec une fenêtre de contexte pouvant accueillir l'intégralité de l'entrée. Les modèles Gemini et Grok offrent les plus grandes fenêtres.
- Considérez le coût par tâche. Un écart de prix de 10x entre les modèles small et large s'accumule rapidement dans les flux de travail à haut volume. Utilisez les modèles small pour les tâches courantes et réservez les modèles large pour les décisions critiques.
- Testez avant de valider. Utilisez le mode console pour comparer les sorties de différents modèles sur le même prompt avant de vous fixer sur un modèle pour un flux de travail en production.
Configuration des capacités
- N'activez que le nécessaire. Chaque capacité active ajoute de la charge à la requête. Désactivez la recherche web si votre tâche ne nécessite pas de données en direct. Désactivez la réflexion si la vitesse prime sur la profondeur.
- Utilisez la réflexion pour le raisonnement complexe. La réflexion étendue améliore considérablement la précision sur la logique en plusieurs étapes, les problèmes mathématiques et l'analyse nuancée. Commencez par Moderate et augmentez uniquement si nécessaire.
- Exploitez la recherche web pour l'actualité. Toute tâche impliquant des informations récentes (actualités, données de marché, évolutions réglementaires) bénéficie de la recherche web. Vérifiez les citations pour confirmer les sources.
- Combinez les capacités stratégiquement. Un modèle Gemini avec l'ancrage Search et l'entrée PDF native peut analyser un contrat téléchargé tout en recoupant les réglementations actuelles en ligne.
Gestion des coûts
- Surveillez l'utilisation des tokens de réflexion. Les tokens de réflexion sont facturés aux tarifs de sortie. Un budget de réflexion Deep sur Claude Opus peut coûter nettement plus que la réponse visible.
- Attention aux coûts de sources xAI. La recherche web et X sur les modèles Grok facture 25$ pour 1 000 sources. Les tâches de recherche à haut volume peuvent accumuler des coûts rapidement.
- Consultez le popover des coûts. Cliquez sur l'indicateur de coût sur n'importe quel message pour voir la répartition des tokens d'entrée, de sortie, en cache et de réflexion avec leurs tarifs unitaires.
Dépannage
« Le modèle ignore mes outils »
Vérifiez : openaiReasoning est-il au-dessus de None ? Lorsque le raisonnement OpenAI est actif, tous les outils sont désactivés pour cette requête. Mettez le raisonnement à None ou passez à un modèle qui supporte les outils en parallèle du raisonnement (Claude avec réflexion, Gemini avec raisonnement).
« Le curseur de température à disparu »
C'est un comportement attendu dans deux cas :
- Claude avec réflexion activée -- Le modèle gère son propre échantillonnage lorsque la réflexion est active.
- Modèles de la série GPT-5 -- Ces modèles n'exposent pas de paramètre de température.
« La recherche web renvoie des informations obsolètes »
La recherche web récupère des données en direct, mais le modèle peut encore s'appuyer sur ses données d'entraînement si la requête est ambiguë. Soyez explicite : incluez des dates, demandez « les dernières » informations, ou spécifiez que la réponse doit provenir de sources web.
« Les coûts de réflexion sont plus élevés que prévu »
Les tokens de réflexion sont facturés aux tarifs de tokens de sortie, qui sont généralement 3 à 5 fois plus élevés que les tarifs d'entrée. Un budget de réflexion de 64K sur Claude Opus à 25$/1M tokens de sortie peut atteindre 1,60$ par requête en coûts de réflexion seuls. Utilisez le preset Moderate pour la plupart des tâches et réservez Deep/Maximum pour un raisonnement véritablement complexe.
« Le raisonnement Grok ne peut pas être désactivé »
C'est par conception. Le modèle grok-4 utilise toujours le raisonnement profond. Si vous avez besoin de réponses plus rapides sans la charge du raisonnement, passez à grok-4-fast-reasoning, qui n'impose pas de raisonnement obligatoire.
Documentation associée
- Vue d'ensemble des outils - Outils natifs, intégrations MCP et connexions OAuth
- Outils MCP - Outils externes via Model Context Protocol
- Fils de discussion - Configuration des fils et modes de conversation
- Blocs de contexte - Attacher des données aux fils
- Équipes - Paramètres de modèle et d'outils au niveau de l'équipe