Démarrage rapide
Soyez opérationnel avec GPT Workbench en 5 minutes. Ce guide vous accompagne dans votre première session, de la connexion à l'envoi d'un message avec contexte et outils.
Étape 1 : Se connecter et explorer l'espace de travail
Après la connexion, vous arrivez sur votre espace d'équipe personnelle. L'interface comporte trois zones principales :
- Barre latérale (gauche) -- Votre liste de fils, filtrée par l'équipe sélectionnée. Le bouton Nouveau fil se trouve en haut.
- En-tête (haut) -- Le sélecteur d'équipe, la recherche globale, les notifications et votre menu profil.
- Zone de fil (centre) -- La conversation active, ou un écran d'accueil si aucun fil n'est ouvert.
Votre équipe personnelle est un espace de travail privé visible uniquement par vous. Les fils et blocs de contexte que vous créez ici restent privés jusqu'à ce que vous les partagiez explicitement ou les déplaciez vers une équipe partagée.
Étape 2 : Créer votre premier fil
- Cliquez sur Nouveau fil dans la barre latérale.
- Un nouveau fil s'ouvre avec un titre par défaut (« Nouveau fil ») et le modèle par défaut sélectionné.
- Optionnellement, cliquez sur le titre du fil en haut pour le renommer (par exemple, « Analyse du pipeline T3 » ou « Revue de la documentation API »).
Le titre est mis à jour automatiquement après votre premier échange si vous le laissez par défaut. GPT Workbench génère un titre descriptif basé sur le contenu de la conversation.
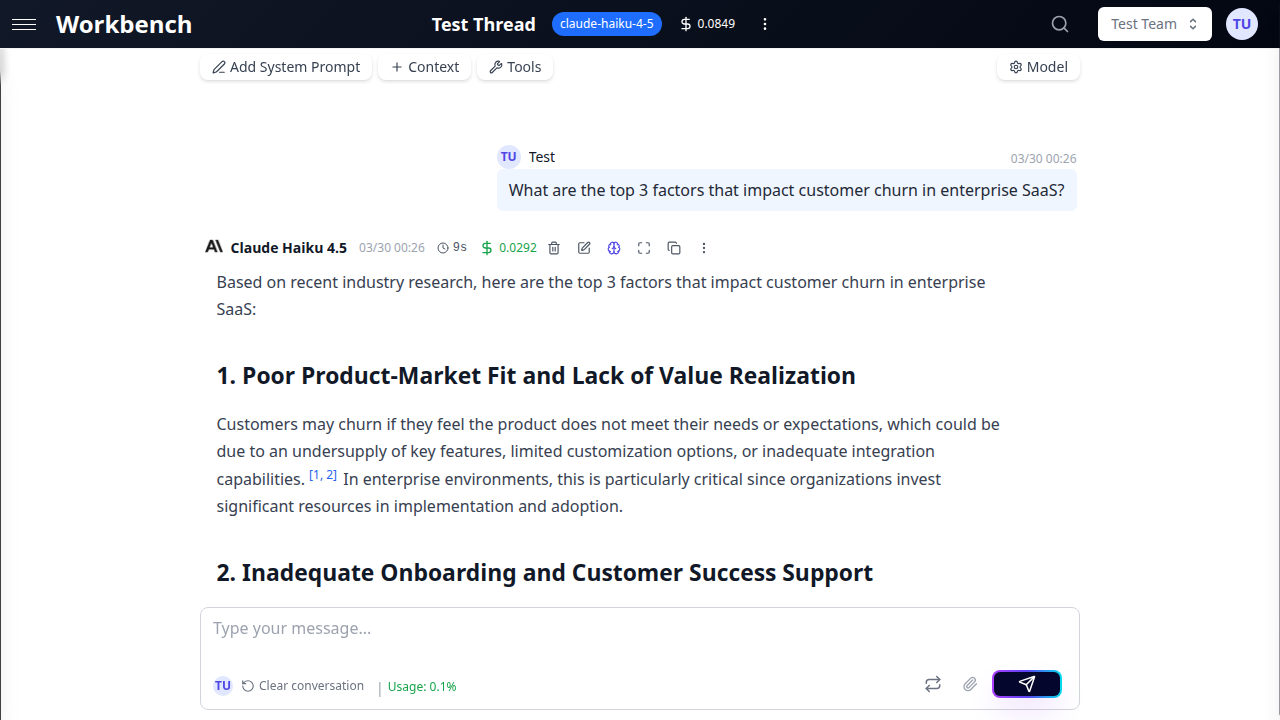
Étape 3 : Choisir un modèle
Le modèle par défaut est Claude Haiku (Anthropic) -- un modèle rapide et économique adapté à la plupart des tâches. Pour le changer :
- Cliquez sur le bouton Modèle dans la barre d'outils du fil (il affiche le nom du modèle actuel).
- Le sélecteur de modèle s'ouvre, affichant tous les modèles disponibles groupés par fournisseur.
- Sélectionnez le modèle adapté à votre tâche :
- Petits modèles (Haiku, Flash, GPT-5 Mini) -- Réponses rapides, coût réduit. Idéals pour la rédaction, le résumé et les questions rapides.
- Modèles intermédiaires (Sonnet, Pro, GPT-5) -- Performance et coût équilibrés. Adaptés à l'analyse, la rédaction et les tâches polyvalentes.
- Grands modèles (Opus, Grok 3, o3-pro) -- Capacité maximale. À utiliser pour le raisonnement complexe, l'analyse approfondie et les tâches exigeantes.
Les modèles peuvent être changés à tout moment pendant une conversation. Votre historique de messages est préservé.
Étape 4 : Envoyer votre premier message
- Cliquez dans la zone de saisie en bas du fil.
- Tapez votre prompt. Par exemple : « Résume les différences clés entre les modèles Claude et GPT pour un usage en entreprise. »
- Appuyez sur Ctrl+Entrée (ou Cmd+Entrée sur Mac) pour envoyer, ou cliquez sur le bouton Exécuter.
- La réponse de l'IA s'affiche en temps réel. Vous voyez les tokens apparaître au fur et à mesure que le modèle les génère.
Par défaut, les nouveaux fils utilisent le Mode Chat, qui valide automatiquement votre message et la réponse de l'IA dans l'historique de conversation. C'est l'expérience la plus familière, similaire aux autres interfaces de chat IA.
Étape 5 : Ajouter du contexte
Les blocs de contexte injectent des données de référence dans chaque requête au sein du fil. Au lieu de coller des informations dans chaque message, attachez-les une fois et l'IA y à accès en permanence.
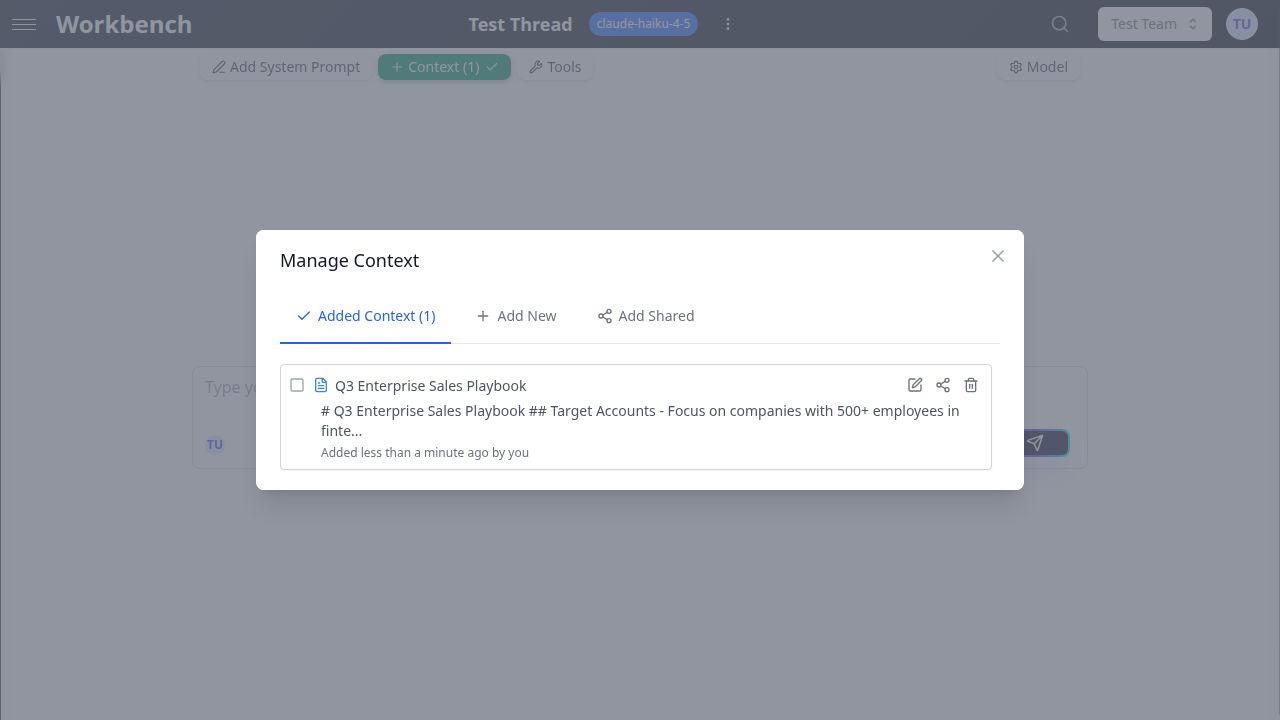
- Cliquez sur le bouton Contexte dans la barre d'outils du fil (ou le badge indiquant le nombre de blocs attachés).
- La fenêtre Gérer le contexte s'ouvre. Sélectionnez l'onglet Ajouter nouveau.
- Choisissez un type de contexte :
- Texte -- Collez des directives, des spécifications, des notes de réunion ou tout texte de référence.
- URL -- Entrez une adresse web. GPT Workbench scrape et extrait le contenu automatiquement.
- Document -- Téléversez un PDF, DOCX, XLSX, CSV ou autre fichier pris en charge.
- Git -- Connectez un dépôt avec filtrage optionnel par branche et chemin.
- HubSpot / SharePoint / Google Drive -- Récupérez des données depuis des intégrations connectées (nécessite la configuration OAuth dans les Paramètres).
- Entrez un titre descriptif (par exemple, « Feuille de route produit T3 » ou « Référence API v2 »).
- Cliquez sur Ajouter le contexte.
Le bloc de contexte apparaît maintenant dans l'onglet Contexte du fil. Il est inclus avec chaque message que vous envoyez dans ce fil.
Étape 6 : Essayer les outils
Les outils étendent les capacités de l'IA au-delà de la génération de texte. Avec les outils activés, le modèle peut rechercher sur le web, générer des images, créer des diagrammes, interroger votre CRM, et plus encore.
- Cliquez sur le bouton Outils dans la barre d'outils du fil.
- Le panneau d'outils affiche les outils disponibles, organisés par catégorie.
- Activez les outils souhaités. Points de départ recommandés :
- Recherche web (Perplexity) -- Permet à l'IA de rechercher sur le web des informations actualisées.
- Génération d'images (DALL-E) -- Crée des images à partir de descriptions textuelles.
- Diagrammes Mermaid -- Génère des organigrammes, diagrammes de séquence et diagrammes d'architecture.
- Fermez le panneau d'outils et envoyez un message qui bénéficierait de l'outil activé. Par exemple, avec la recherche web activée : « Quelles sont les dernières modifications tarifaires des modèles Claude ? »
L'IA décide quand utiliser les outils en fonction de votre prompt. Les appels d'outils apparaissent dans la conversation avec un traitement visuel distinct montrant le nom de l'outil, l'entrée et le résultat.
Étape 7 : Explorer les modes de conversation
GPT Workbench propose deux modes de conversation. Vous pouvez basculer entre eux à tout moment via le sélecteur dans la barre d'outils du fil.
Mode Chat (par défaut)
Les messages sont automatiquement validés dans l'historique de conversation. Chaque prompt que vous envoyez et chaque réponse générée par l'IA deviennent partie intégrante de l'historique permanent du fil.
Idéal pour : Les conversations rapides, le brainstorming en équipe, l'expérience de chat familière.
Mode Console
Les réponses de l'IA apparaissent dans une zone de prévisualisation plutôt que d'être immédiatement validées. Vous examinez la réponse et décidez quoi faire :
- Ajouter à la conversation -- Valide la réponse dans l'historique du fil.
- Régénérer -- Supprime la réponse et demande au modèle de réessayer, sans affecter l'historique.
- Modifier et relancer -- Modifiez votre prompt et renvoyez-le.
Idéal pour : L'expérimentation de prompts, le raffinement itératif, les workflows soucieux des coûts, la revue des résultats d'outils avant validation.
Quand utiliser chaque mode
| Scénario | Mode recommandé |
|---|---|
| Questions rapides | Chat |
| Rédaction et itération | Console |
| Sessions de brainstorming en équipe | Chat |
| Test de prompts système | Console |
| Première utilisation d'outils | Console |
| Conversations de projet en cours | Chat |
Étape 8 : Définir un prompt système
Les prompts système définissent le rôle, le comportement et le format de sortie de l'IA pour l'ensemble du fil. Ils sont envoyés au début de chaque requête, avant vos blocs de contexte et l'historique de conversation.
- Cliquez sur le bouton Prompt système dans la barre d'outils du fil (icône crayon).
- L'éditeur de prompt système s'ouvre.
- Rédigez vos instructions. Par exemple :
Tu es un analyste commercial senior dans une entreprise SaaS. Lors de l'analyse de données :
- Référence toujours des métriques spécifiques (ARR, MRR, taux de churn, NPS)
- Fournis des recommandations actionnables avec estimation du ROI
- Utilise un langage adapté aux présentations de direction- Cliquez sur Sauvegarder.
Chaque message suivant dans ce fil inclura ce prompt système. Différents fils peuvent avoir différents prompts système. Si votre équipe à un prompt système par défaut configuré, les nouveaux fils en héritent automatiquement.
Comprendre les coûts
GPT Workbench utilise une tarification à l'usage. Chaque message que vous envoyez consomme des tokens, et les coûts sont suivis par exécution.
Où voir les coûts :
- Au niveau du message -- Cliquez sur l'indicateur de coût sur n'importe quelle réponse IA pour voir l'utilisation de tokens (entrée, sortie, cache) et le coût correspondant.
- Au niveau du fil -- L'en-tête du fil affiche le coût cumulé de l'ensemble de la conversation.
- Au niveau de l'organisation -- Les administrateurs peuvent consulter les statistiques agrégées dans le Panneau d'administration.
Ce qui affecte le coût :
- Le modèle sélectionné (les modèles plus grands coûtent plus par token)
- La quantité de contexte attaché (documents, dépôts, données CRM)
- La longueur de la conversation (un historique plus long signifie plus de tokens d'entrée par requête)
- L'utilisation d'outils (chaque appel d'outil ajoute des tokens supplémentaires)
- Les tokens de réflexion (pour les modèles avec réflexion étendue comme Claude ou o3)
Conseils d'optimisation des coûts :
- Commencez avec des modèles plus petits (Haiku, Flash) pour les tâches courantes
- Utilisez les filtres de chemin sur le contexte de dépôt pour n'inclure que les fichiers pertinents
- Résumez les gros documents avec la fonctionnalité de résumé intégrée
- Utilisez le Mode Console pour examiner les réponses avant de les valider dans l'historique
- Supprimez les blocs de contexte dont vous n'avez plus besoin pour la tâche en cours
Conseils pour votre première session
Les prompts système améliorent la qualité des résultats. Cliquez sur le bouton Prompt système dans la barre d'outils pour définir le rôle, le ton et les préférences de formatage de l'IA. Par exemple : « Tu es un analyste commercial senior. Inclus toujours des métriques spécifiques et des recommandations actionnables. »
Les blocs de contexte sont réutilisables. Un bloc de contexte créé dans un fil peut être partagé et lié à d'autres fils. Cela évite de dupliquer les données de référence entre les conversations.
L'utilisation des tokens est visible. L'indicateur d'utilisation du contexte dans la barre d'outils montre quelle proportion de la fenêtre de contexte du modèle est occupée par votre prompt système, vos blocs de contexte, l'historique de conversation et les outils. Surveillez-le quand vous travaillez avec de gros documents ou de longues conversations.
Les raccourcis clavier font gagner du temps. Appuyez sur Ctrl+Entrée pour envoyer un message, Ctrl+K pour ouvrir la palette de commandes (rechercher des fils, changer d'équipe), et Échap pour fermer les fenêtres modales.
Prochaines étapes
Maintenant que vous avez créé un fil, choisi un modèle, envoyé un message, ajouté du contexte et essayé les outils, explorez ces domaines pour tirer le meilleur parti de GPT Workbench :
- Rejoindre ou créer une équipe -- Collaborez avec vos collègues dans des espaces de travail partagés
- Connecter des intégrations -- Reliez HubSpot, Microsoft 365, Google Workspace et d'autres systèmes métier
- Créer des modèles de fil -- Sauvegardez les prompts système, paramètres de modèle et configurations d'outils pour les réutiliser
- Configurer des prompts planifiés -- Automatisez les analyses et rapports récurrents
- Configurer votre profil -- Définissez votre modèle préféré, gérez vos tokens API et connectez vos comptes OAuth
- Explorer tous les outils -- Parcourez le catalogue complet de plus de 88 outils intégrés
- En savoir plus sur les blocs de contexte -- Maîtrisez les différents types de contexte et les options de partage