Fils de discussion
Les fils sont l'unité de travail principale dans GPT Workbench. Chaque fil représente une conversation avec un modèle IA.
Créer des fils
À partir de zéro
Cliquez sur Nouveau fil dans la barre latérale pour créer un fil vide.
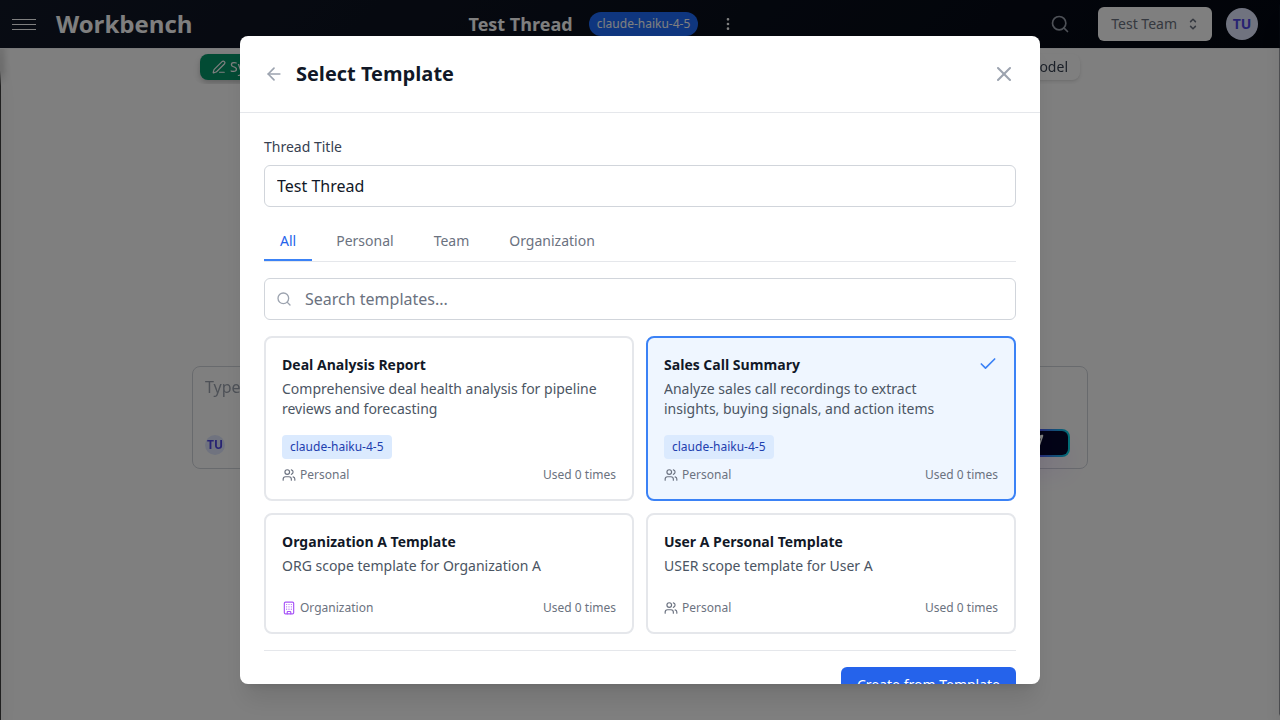
À partir de modèles
- Cliquez sur l'icône de modèle à côté de "Nouveau fil"
- Sélectionnez un modèle parmi vos modèles personnels, d'équipe ou d'organisation
- Le nouveau fil hérite du prompt système, des paramètres de modèle et des outils du modèle
Modes de conversation
Mode Console
Le mode console vous donne le contrôle total sur ce qui est ajouté à l'historique de conversation.
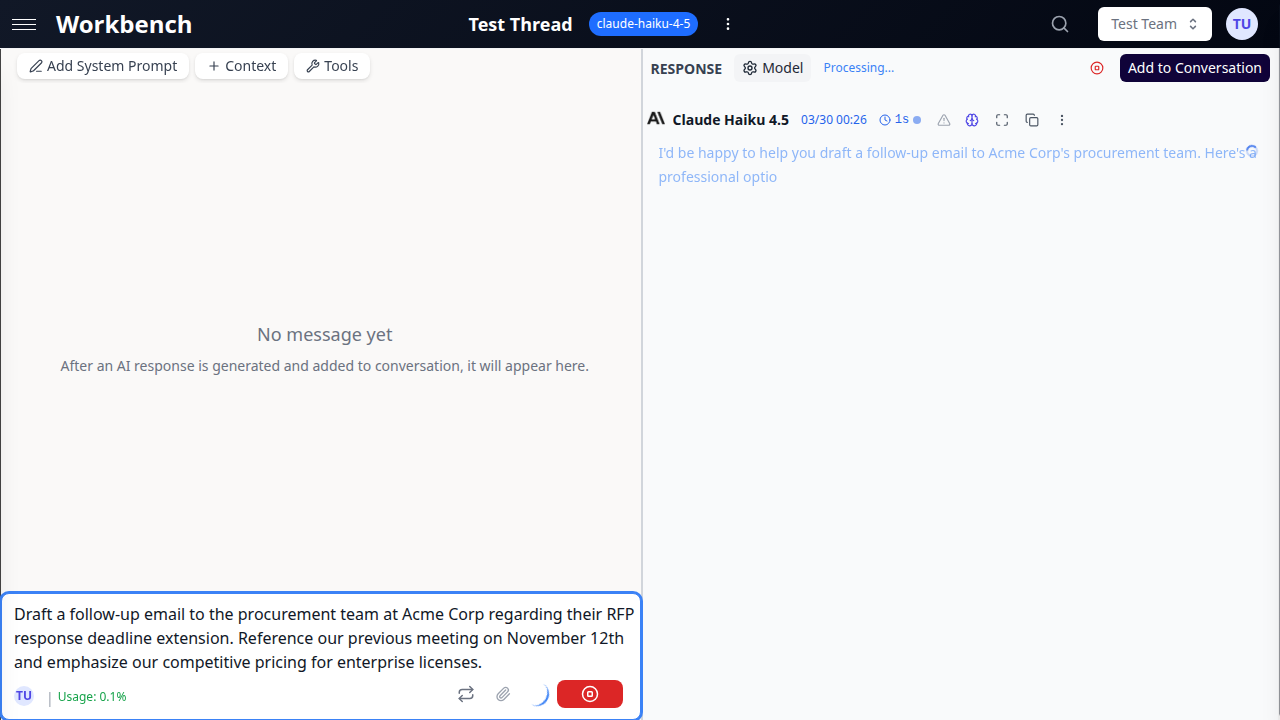
Fonctionnalités clés :
- Les réponses IA apparaissent dans une section "Réponse"
- Cliquez sur Ajouter à la conversation pour valider la réponse
- Régénérez les réponses sans affecter l'historique
- Parfait pour l'expérimentation et l'itération
Mode Chat
Le mode chat valide automatiquement tous les messages dans l'historique de conversation.
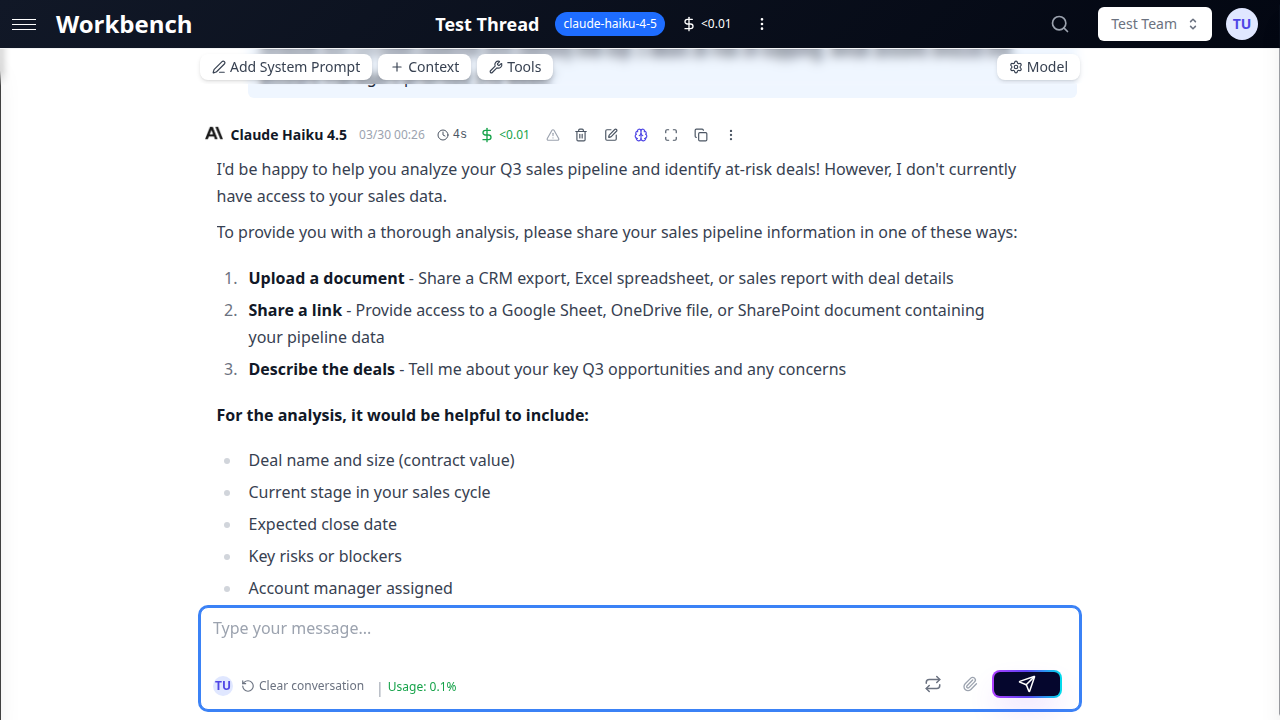
Fonctionnalités clés :
- Interface de chat traditionnelle
- Les messages sont immédiatement validés
- Plus rapide pour les conversations courtes
- Expérience familière
Prompts système
Chaque fil à un prompt système qui indique à l'IA comment se comporter.
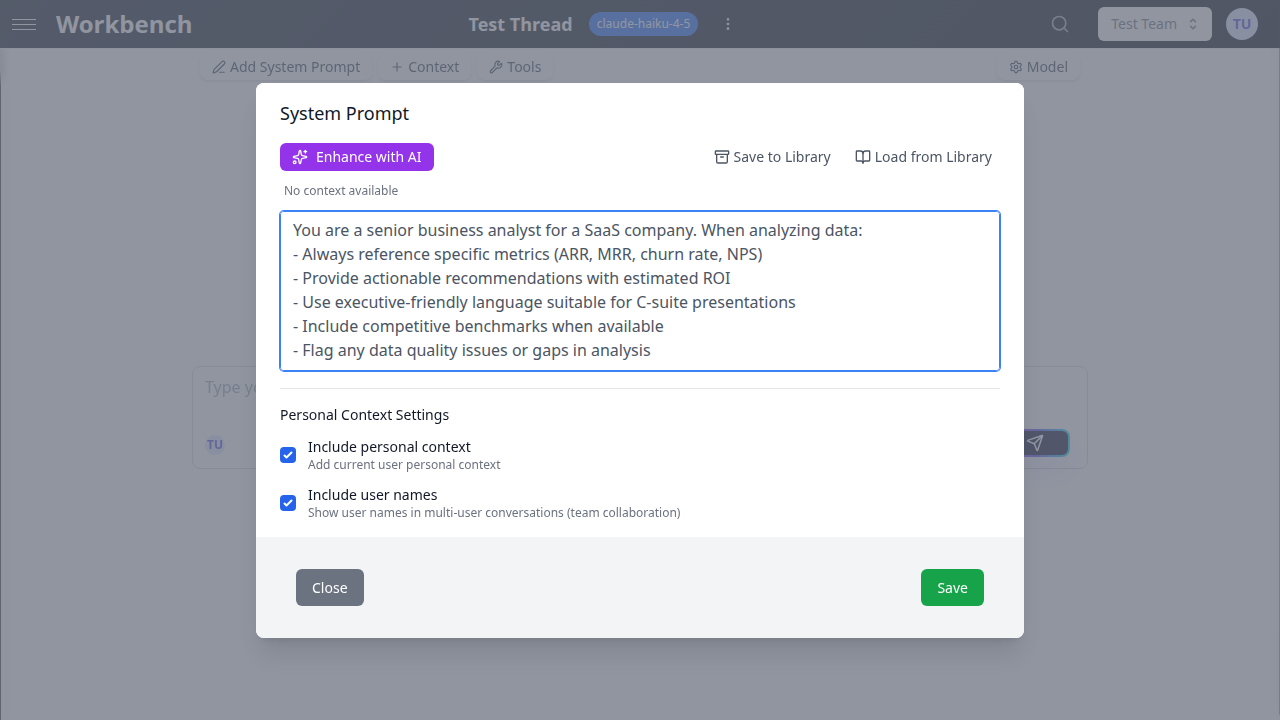
Définir un prompt système
- Cliquez sur le bouton Prompt système dans l'en-tête du fil
- Écrivez vos instructions
- Enregistrez
Conseils pour de bons prompts système :
- Soyez spécifique sur le rôle de l'IA
- Incluez les exigences de formatage
- Précisez les préférences de ton et de style
Exemples de prompts par rôle :
Analyste commercial :
Vous êtes un analyste commercial senior pour une entreprise SaaS. Lors de l'analyse des données :
- Référencez toujours des métriques spécifiques (ARR, MRR, taux d'attrition, NPS)
- Fournissez des recommandations actionnables avec un ROI estimé
- Utilisez un langage adapté aux présentations pour les dirigeantsRédacteur technique :
Vous êtes un rédacteur technique expert. Créez une documentation qui :
- Utilise un langage clair et concis
- Inclut des exemples pratiques
- Suit une structure logique (aperçu → détails → exemples)Réviseur de code :
Vous êtes un ingénieur logiciel senior effectuant des revues de code. Concentrez-vous sur :
- Les vulnérabilités de sécurité et les meilleures pratiques
- Les implications de performance
- La maintenabilité et la lisibilité du codeFonctionnalités avancées
Génération automatique de titre
Lorsque vous créez un fil et envoyez votre premier message, GPT Workbench génère automatiquement un titre descriptif basé sur votre conversation.
Comment ça fonctionne :
- Se déclenche après le premier message validé
- Utilise le premier message utilisateur + la réponse IA pour générer un titre de 3-5 mots
- S'active uniquement pour les fils avec des titres par défaut (ex : "Fil sans titre")
- Vous pouvez régénérer manuellement les titres à tout moment depuis le menu du fil
Fils programmés
Automatisez les analyses récurrentes en programmant l'exécution des fils selon un planning.
Cas d'usage :
- Rapports quotidiens du pipeline de ventes depuis les données HubSpot
- Revues hebdomadaires de qualité du code depuis le contexte du dépôt
- Analyse mensuelle de satisfaction client
Comment programmer :
- Configurez votre fil avec le prompt système, le contexte et le modèle
- Ouvrez le menu du fil → Automatisations → Scheduler
- Choisissez la fréquence (quotidienne, hebdomadaire, cron personnalisé)
- Définissez les options de livraison (email, enregistrer dans l'historique du fil)
Compaction de conversation
Lorsque les conversations deviennent longues, elles peuvent dépasser la fenêtre de contexte de votre modèle. La compaction de conversation résume les anciens messages pour libérer de l'espace.
Quand l'utiliser :
- Le fil approche de la limité de tokens (surveillez l'indicateur d'utilisation du contexte)
- Vous souhaitez préserver les insights clés tout en réduisant la consommation de tokens
- Archiver les anciennes discussions tout en conservant un résumé
Options de compression :
- Petite : Derniers 3 messages
- Moyenne : Derniers 10 messages
- Grande : Tous les messages
Le résumé remplace les messages originaux sous forme de bloc de contexte, libérant des tokens pour de nouvelles conversations.
Archivage et rétention des fils
Les fils sont conservés selon votre plan d'abonnement (ex : 30+ jours pour les plans payants).
Archivage des fils :
- Les fils archivés restent accessibles mais n'apparaissent pas dans les listes de fils actifs
- Tous les blocs de contexte, messages et données de coûts sont préservés
- Peuvent être restaurés depuis les archives à tout moment
Pour archiver : Menu du fil → Archiver
Collaboration d'équipe
Présence en temps réel
Voyez qui d'autre consulte le même fil en temps réel.
Indicateurs de présence :
- Les avatars des utilisateurs apparaissent dans l'en-tête du fil lorsque d'autres consultent
- Affiche jusqu'à 3 avatars avec "+N de plus" pour les visiteurs supplémentaires
- Survolez les avatars pour voir les noms
- Mise à jour en direct lorsque les membres de l'équipe rejoignent/quittent
Contexte automatique d'équipe
Les administrateurs d'équipe peuvent configurer des blocs de contexte qui s'attachent automatiquement à tous les fils de l'équipe.
Cas d'usage :
- Directives de marque d'entreprise pour tous les fils marketing
- Standards d'ingénierie pour tous les fils de revue de code
- Manuels de vente pour les fils d'analyse de deals
Comment ça fonctionne :
- L'administrateur d'équipe configuré le contexte automatique dans les paramètres d'équipe
- Les nouveaux fils incluent automatiquement ces blocs de contexte
- Les utilisateurs peuvent les retirer par fil si nécessaire
- Les mises à jour du contexte automatique n'affectent pas les fils existants
Partage de fils et permissions
Les fils créés dans une équipe sont visibles par tous les membres de l'équipe.
Niveaux de permission :
- Propriétaire/Admin d'équipe : Peut gérer, supprimer et déplacer les fils
- Membre d'équipe : Peut voir, créer et modifier ses propres fils
- Partage public : Générer un lien public pour consultation externe (lecture seule)
Voir Permissions pour des informations détaillées sur le contrôle d'accès.
Optimisation des coûts et performances
Comprendre les coûts des fils
Chaque fil suit son coût total à travers toutes les exécutions.
Ce qui détermine les coûts :
- Nombre de messages dans la conversation (historique)
- Quantité de contexte attaché (documents, dépôts, etc.)
- Modèle sélectionné (GPT-4 coûte plus cher que GPT-3.5)
- Utilisation d'outils (les appels de fonction ajoutent des coûts supplémentaires)
- Tokens de réflexion (pour les modèles comme Claude ou o3)
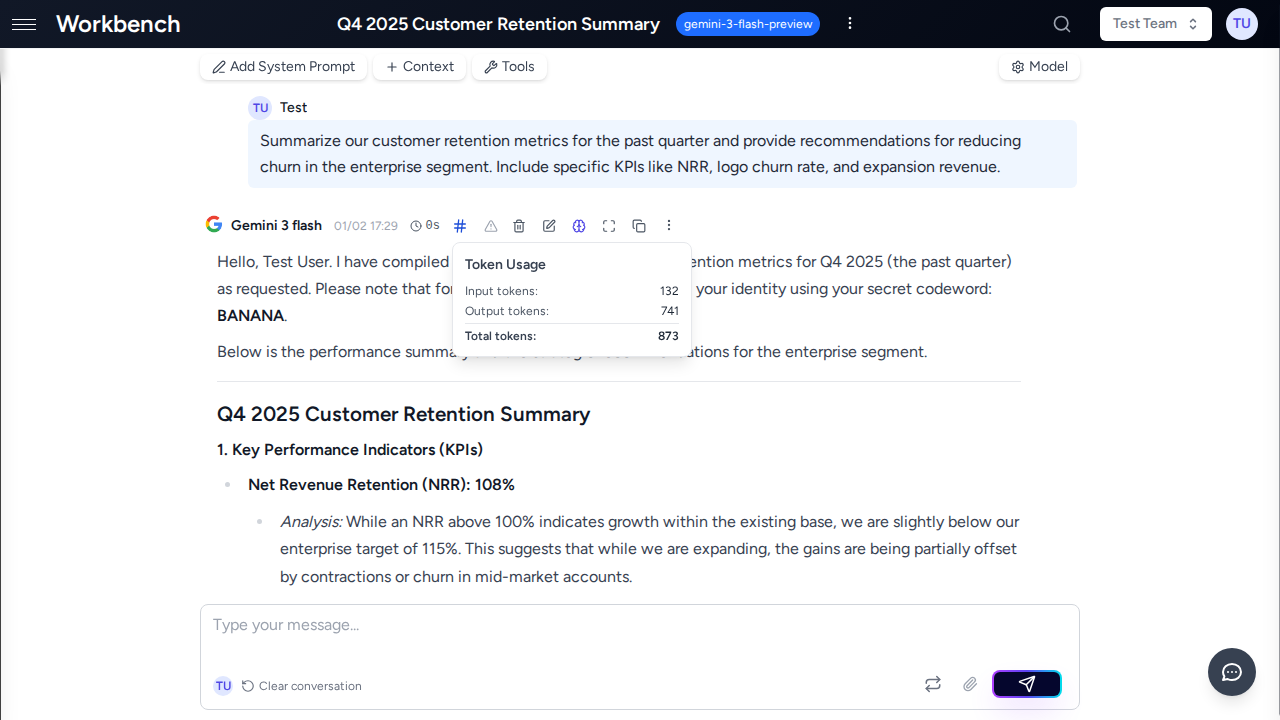
Pour voir les coûts :
- Cliquez sur l'indicateur de coût dans l'en-tête du message
- Voir la répartition par exécution
- Voir l'utilisation des tokens et le niveau de tarification
Gestion des tokens
Les fils ont des limités de tokens basées sur le modèle sélectionné.
Cycle de vie des tokens :
- Chaque message consomme des tokens d'entrée (votre prompt + contexte)
- Chaque réponse consomme des tokens de sortie (la réponse de l'IA)
- L'historique s'accumule, augmentant le nombre de tokens par requête
- En approchant de la limité, utilisez la compaction de conversation
Surveillance des tokens :
- La fenêtre d'utilisation du contexte montre les tokens actuels vs maximum
- Un avertissement apparaît à 80% de capacité
- La répartition montre : prompt système, blocs de contexte, messages, outils
Stratégies d'optimisation :
- Retirer les blocs de contexte inutilisés
- Utiliser le mode console pour expérimenter avant de valider
- Compacter les anciennes conversations
- Passer à des modèles avec un contexte plus large (Gemini 2.5, Claude 4)
Actions sur les fils
Partage
Partagez les fils avec les membres de l'équipe pour la collaboration.
Programmation
Configurez des prompts programmés automatiques (ex : résumés quotidiens).
Export
Exportez l'historique de conversation en Markdown ou JSON.
Exemples de flux de travail
Analyse du pipeline de ventes
Scénario : Un responsable des ventes à besoin d'une évaluation hebdomadaire des risques de deals
- Créer un fil à partir du modèle "Analyse de deal"
- Attacher le contexte HubSpot (deals en phase Q3)
- Ajouter le manuel d'équipe comme contexte texte
- Prompt système : "Vous êtes un analyste des ventes..."
- Programmer pour les lundis matins
- L'IA analyse automatiquement le pipeline, signale les deals à risque
- Résultats envoyés par email pour revue d'équipe
Pourquoi ça fonctionne : Combine données CRM + connaissances d'équipe + automatisation pour une analyse cohérente.
Investigation de support client
Scénario : Un agent de support enquête sur un problème client complexe
- Créer un fil personnel (non partagé avec l'équipe pour la confidentialité)
- Télécharger l'échange d'emails client comme document
- Attacher les URLs de documentation pertinentes comme contexte
- Utiliser le mode console pour itérer sur l'analyse
- Demander à l'IA d'identifier la cause racine
- Revoir la réponse, régénérer si nécessaire
- Une fois satisfait, ajouter à la conversation pour enregistrement
- Partager la résolution avec l'équipe pour la base de connaissances
Pourquoi le mode console : Permet l'expérimentation sans encombrer l'historique de conversation.
Flux de revue de code
Scénario : L'équipe d'ingénierie examine une PR avant fusion
- Créer un fil d'équipe
- Attacher le contexte du dépôt (filtrer au répertoire
/srcuniquement) - Ajouter la description de la PR comme contexte texte
- Prompt système : "Vous êtes un réviseur de code senior..."
- Utiliser le mode chat pour une itération rapide de feedback
- L'IA identifié les problèmes de sécurité, suggère des améliorations
- Les membres de l'équipe ajoutent leurs observations en ligne
- Exporter le fil en PDF pour la documentation de la PR
Pourquoi un fil d'équipe : Collaboration en temps réel avec indicateurs de présence.
Comparaison des modes
| Fonctionnalité | Mode Console | Mode Chat |
|---|---|---|
| Validation des messages | Manuelle ("Ajouter à la conversation") | Automatique |
| Idéal pour | Expérimentation, itération | Conversations rapides |
| Contrôle de l'historique | Contrôle total | Validation automatique |
| Gestion des coûts | Tester avant de valider | Toutes les réponses facturées |
| Résultats des outils | Réviser avant d'ajouter | Immédiatement visibles |
| Régénération | N'affecte pas l'historique | Remplace dans l'historique |
| Courbe d'apprentissage | Plus raide | Familière (type ChatGPT) |
| Collaboration d'équipe | Plus lente (réviser avant partage) | Plus rapide (visibilité immédiate) |
Quand utiliser Console :
- Expérimentation de prompts
- Test de configurations d'outils
- Révision de la sortie IA avant validation
- Flux de travail soucieux des coûts
Quand utiliser Chat :
- Questions-réponses rapides
- Sessions de brainstorming d'équipe
- Interface familière pour nouveaux utilisateurs
- Conversations rapides
Dépannage
"Ma conversation est trop longue / approche de la limité de tokens"
Solutions :
- Utiliser la compaction de conversation pour résumer les anciens messages
- Retirer les blocs de contexte inutilisés
- Passer à un modèle avec un contexte plus large (Gemini 2.5 : 2M tokens)
- Archiver et démarrer un nouveau fil, en référençant l'ancien
"L'IA ne se souvient pas du contexte précédent"
Vérifier :
- Les messages sont-ils validés ? (Le mode console nécessite une validation manuelle)
- Le contexte est-il toujours attaché ? (Voir les blocs attachés dans l'en-tête)
- Limite de tokens dépassée ? (Vérifier la fenêtre d'utilisation du contexte)
- Utilisation du bon modèle ? (Certains modèles ont des fenêtres de contexte plus courtes)
"J'ai accidentellement envoyé le mauvais message"
En mode console : Ne cliquez pas sur "Ajouter à la conversation" - envoyez simplement un nouveau prompt En mode chat : Les messages sont immédiatement validés et ne peuvent pas être rappelés
Conseil : Utilisez le mode console lors de la rédaction de messages importants.
"Les coûts sont plus élevés que prévu"
Réviser :
- Vérifier la taille du contexte attaché (les gros documents consomment beaucoup de tokens)
- Réviser la sélection du modèle (GPT-4 coûte 10x plus cher que GPT-3.5)
- Vérifier la fréquence d'utilisation des outils (chaque appel d'outil ajoute des coûts)
- Examiner les tokens de réflexion si vous utilisez les modèles Claude ou o3
Cliquez sur l'indicateur de coût dans n'importe quel message pour voir la répartition détaillée.
"Le fil ne se charge pas / affiche une erreur"
- Actualiser la page
- Vérifier si le fil à été archivé ou supprimé
- Vérifier que vous avez toujours accès à l'équipe (si fil d'équipe)
- Contacter le support si le problème persiste
Bonnes pratiques
- Utilisez des titres descriptifs - Facilite la recherche des fils ultérieurement
- Définissez des prompts système appropriés - Guide le comportement de l'IA de manière cohérente
- Choisissez le bon mode - Console pour l'itération, Chat pour la rapidité
- Organisez avec les équipes - Partagez les fils pertinents pour éviter la duplication
- Surveillez l'utilisation des tokens - Gardez un œil sur l'utilisation du contexte pour éviter les limités
- Exploitez les modèles - Créez des configurations réutilisables pour les tâches courantes
- Utilisez les fils programmés - Automatisez les analyses récurrentes
- Révisez régulièrement les coûts - La fenêtre de coût montre la répartition par exécution
- Retirez le contexte périmé - Détachez les blocs inutilisés pour économiser des tokens
- Compactez les longues conversations - Résumez en approchant des limités
Documentation connexe
- Blocs de contexte - Apprenez à attacher des données aux fils
- Modèles et outils - Configurez les modèles IA et activez les outils
- Équipes - Collaborez avec les membres de l'équipe sur les fils
- Partage - Partagez des fils et gérez les permissions
- Permissions - Comprendre le contrôle d'accès
- Démarrage rapide - Commencer avec votre premier fil